标题:[转帖]开源开放 | 《大词林》开源 75 万核心实体和围绕核心实体的细粒度概念、关系列表
1.《大词林》介绍
《大词林》(http://101.200.120.155/)由 哈尔滨工业大学社会计算与信息检索研究中心秦兵教授和刘铭副教授主持研制,是一个自动构建的大规模开放域中文知识库。自2014年11月推出《大词林》第一版,第一版的《大词林》包含了自动挖掘的实体和细粒度的上位概念词,类似一个大规模的汉语词典,其特点在于自动构建、自动扩充,细粒度的上下位层次关系。2019年8月推出的第二版《大词林》引入了实体的义项和关系、属性数据,将每一个实体的义项唯一对应到细粒度的上位词概念路径,让《大词林》中实体的含义更加清晰。
相比于传统的开放域实体知识库,《大词林》的特点在于:
- 构建过程不需要领域专家的参与,而是基于多信息源自动获取实体类别并对可能的多个类别进行层次化,从而达到知识库自动构建的效果。
- 其数据规模可以随着互联网中实体词的更新而扩大,很好地解决了以往的人工构建知识库对开放域实体的覆盖程度极为有限的问题。
- 《大词林》是一个树状的网络,每一个实体的义项均能够唯一对应到细粒度的上位词概念路径且具有丰富的实体和关系数据,能够更加清晰明确的展示实体的含义。
2. 开源数据规模和用途
本次,我们开源了《大词林》中的 75万的核心实体词,以及 这些核心实体词对应的细粒度概念词(共 1.8万概念词, 300万实体-概念元组),还有 相关的关系三元组(共 300万)。这75万核心实体列表涵盖了常见的人名、地名、物品名等术语。概念词列表则包含了细粒度的实体概念信息。借助于细粒度的上位概念层次结构和丰富的实体间关系,本次开源的数据能够为人机对话、智能推荐、等应用技术提供数据支持。
在http://101.200.120.155/browser/页面下有全部开源数据的下载链接,用户也可直接利用下面的链接直接下载全部数据。
下载地址:
https://pan.baidu.com/s/1NG8xybrEGTVYPepMM12xNw
提取码:mwmj
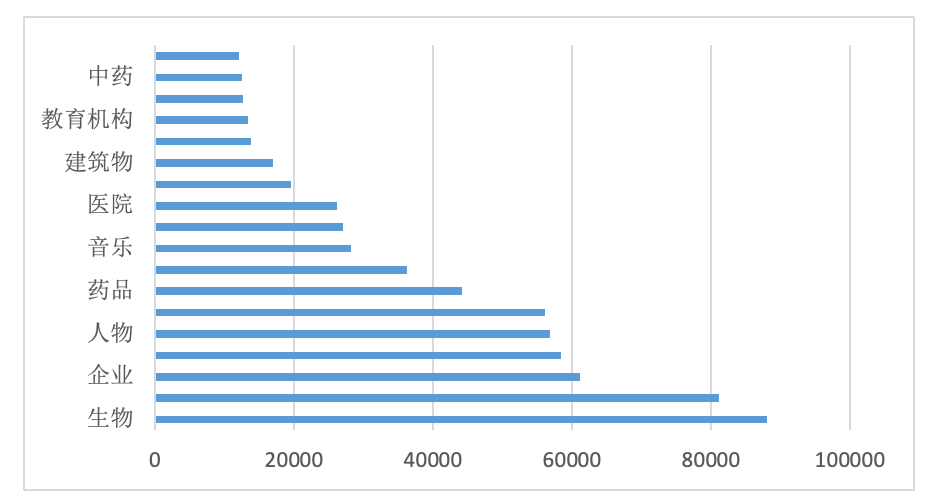
图1 开源实体的抽样分布情况
数据格式如下:
-
实体词表, entity.txt
实体名1
实体名2
……
- 概念词表, concept.txt
概念词1
概念词2
……
- 实体-概念词表, hyper.txt
实体名1,上位词1
……
实体名2,上位词2
……
-
实体三元组表, triple.txt
实体名1,关系名1,实体名1
实体名1,关系名2,实体名2
……
为方便用户查看不同类别下的实体,将本次开源的实体中部分常见的类别放在此demo下http://101.200.120.155/browser/。为加快加载速度,此demo仅展示了类别下的抽样实体。
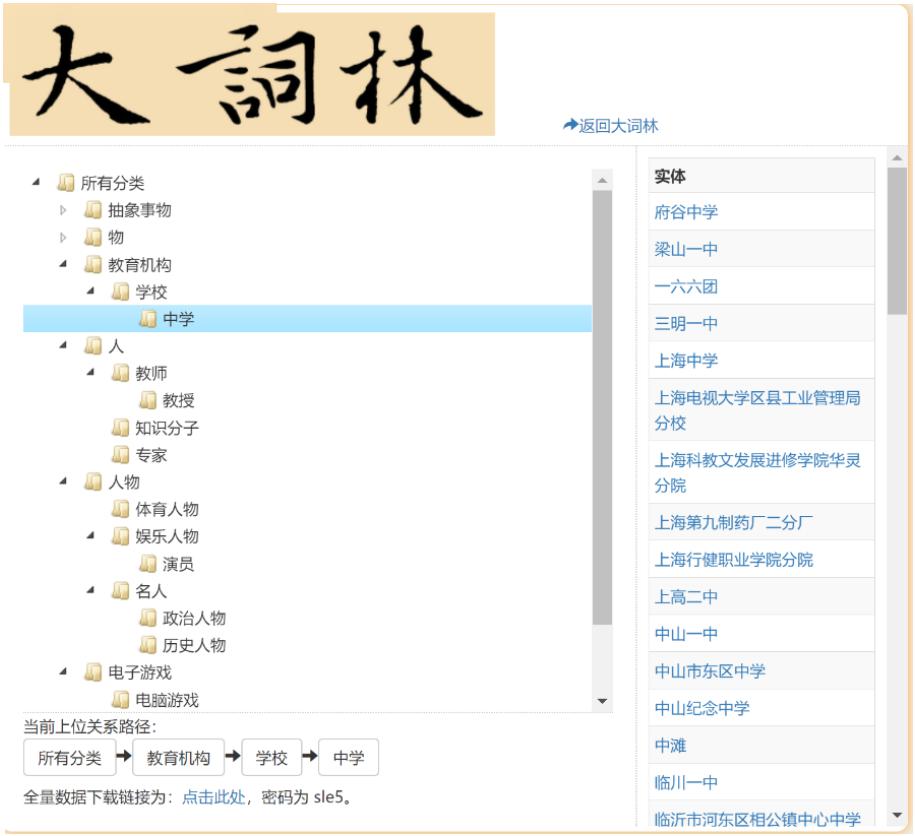
图2 开源实体按类别浏览
3. 结语:
如需要查询更多的数据可使用《大词林》系统网站(http://101.200.120.155/),该系统支持用户查询任意实体,并以有向图的形式展现实体的层次化概念体系,同时支持以目录方式浏览部分公开的知识库。经过如上的改进后,目前《大词林》2.0版已拥有实体 30,102,845(三千万),上位词 182,079(十八万),优质的实体上下位关系对 15,577,846(一千五百万对),属性-值对 79,568,791(七千九百万对),关系(属性)数 436,961(四十三万)。有关《大词林》的功能介绍及详细的接口说明请联系 mliu@ir.hit.edu.cn。
附此次开源数据协议:
《大词林》(http://101.200.120.155/)是一个自动构建的大规模开放域中文知识库,由哈尔滨工业大学社会计算与信息检索研究中心秦兵教授和刘铭副教授主持研制。本次开源的是《大词林》中75万核心实体和核心实体对应的1.8万细粒度概念词表,其中核心实体涵盖了包括常见的人名、地名、物品名等术语,概念词列表则包含了细粒度的实体概念信息。同时开源的还包括由实体和概念形成的上下位关系列表(300万)和实体对应的关系三元组列表(300万)。本批数据面向国内外大学、公益性科研机构以及个人研究者免费开放,上述开放资源无需付费使用,但不可以用于商业。如需用于商业,或希望获得完整版数据,请向哈工大刘铭老师(mliu@ir.hit.edu.cn)咨询。如果您在《大词林》开源数据基础上发表论文或取得科研成果,请您在发表论文和申报成果时声明“使用了哈工大社会计算与信息检索研究中心研制的《大词林》(英文: HIT-SCIR BigCilin)”,同时发信给 mliu@ir.hit.edu.cn,说明发表论文或申报成果的题目、出处等。