��1 ֪ʶͼ��������
�����������ȸ���֪ʶͼ�ļ�����ͼ��Ȼ�����֪ʶͼ�����Ĺؼ�������������ϵ��ȡ������֪ʶ�ںϼ�����ʵ�����Ӽ�����֪ʶ����������
����1.1 ֪ʶͼ������ͼ
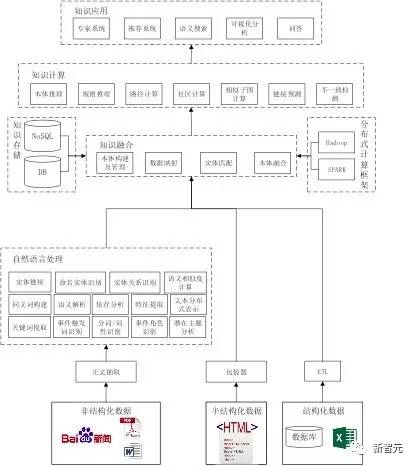
��������֪ʶͼ����ҪĿ���ǻ�ȡ�����ġ��ü�����ɶ���֪ʶ���ڻ��������ٷ�չ�Ľ��죬֪ʶ���������ڷǽṹ�����ı����ݡ�������ṹ���ı������ҳ�Լ�����ϵͳ�Ľṹ�������С�Ϊ�˲�����ι���֪ʶͼ�ף����ĸ����˹���֪ʶͼ�ļ�����ͼ���ü�����ͼ��ͼ1��ʾ����������ͼ��Ҫ��Ϊ�������֣���һ��������֪ʶ��ȡ����Ҫ������δӷǽṹ������ṹ�����Լ��ṹ�������л�ȡ֪ʶ���ڶ����������ںϣ���Ҫ������ν���ͬ����Դ��ȡ��֪ʶ�����ںϹ�������֮��Ĺ���������������֪ʶ���㼰Ӧ�ã���һ���ֹ�ע���ǻ���֪ʶͼ���㹦���Լ�����֪ʶͼ��Ӧ�á�
����1.1.1 ֪ʶ��ȡ
�����ڴ����ǽṹ�����ݷ��棬����Ҫ���û��ķǽṹ��������ȡ���ġ�Ŀǰ�Ļ��������ݴ����Ŵ����Ĺ�棬������ȡ����ϣ����Ч�Ĺ��˹���ֻ�����û���ע���ı����ݡ����õ������ı�����Ҫͨ����Ȼ���Լ���ʶ�������е�ʵ�壬ʵ��ʶ��ͨ�������ַ�����һ�����û�������һ��֪ʶ�������ʹ��ʵ�����ӽ������п��ܵĺ�ѡʵ�����ӵ��û���֪ʶ���ϡ���һ���ǵ��û�û��֪ʶ������Ҫʹ������ʵ��ʶ����ʶ�������е�ʵ�塣�������д���ʵ��ı�������ƻ���Ҫ����ʵ����ͬ��ʱ�����������ʹ��ͬʵ�������ͬ����������ʶ��ʵ��Ĺ����п��ܻ��õ��ִʡ����Ա�ע���Լ����ѧϰģ������Ҫ�õ��ֲ�ʽ�������������ͬʱΪ�˵õ���ͬ���ȵ�֪ʶ��������Ҫ��ȡ���еĹؼ��ʣ���ȡ���µ�DZ������ȡ����û����ʵ�������Ҫ��עʵ���Ĺ�ϵ�����dz�Ϊʵ���ϵʶ����Щʵ���ϵʶ��ķ��������þ䷨�ṹ������ȷ������ʵ���Ĺ�ϵ���������Щ�㷨�л�����������������������������û����������ȡʵ���Ĺ�ϵ�������ȡһ���¼�����ϸ���ݣ���ô����Ҫȷ���¼��Ĵ����ʲ���ȡ�¼���Ӧ�����ľ��ӣ�ͬʱʶ���¼�����������ʵ���Ӧ�¼��Ľ�ɫ��
�����ڴ�����ṹ�����ݷ��棬��Ҫ�Ĺ�����ͨ����װ��ѧϰ��ṹ�����ݵij�ȡ�������ڰ�ṹ�����ݾ��д������ظ��ԵĽṹ����˶����ݽ��������ı�ע�������û���ѧ��һ���Ĺ������������վ����ʹ�ù����ͬ���ͻ��߷���ij�ֹ�ϵ�����ݽ��г�ȡ������û������ݴ洢������ϵͳ�����ݿ���ʱ����Ҫͨ�� ETL ���߶��û�����ϵͳ�µ����ݽ���������֯����ϴ��������õ������û�ʹ��Ŀ�����ݡ�
����1.1.2 ֪ʶ�ں�
������֪ʶ�Ӹ�������Դ�»�ȡʱ��Ҫ�ṩͳһ�����ォ��������Դ��ȡ��֪ʶ�ںϳ�һ���Ӵ��֪ʶ�⡣�ṩͳһ����Ľṹ�������ݱ���Ϊ���壬���岻���ṩ��ͳһ�������ֵ䣬�������˸��������Ĺ�ϵ�Լ����ơ�����������û��dz���������ĸ����Լ���ҵ��������������ģ�͡�ͨ������ӳ�似����������������Ͳ�ͬ����Դ��ȡ֪ʶ�дʻ��ӳ���ϵ����������ͬ����Դ�������ں���һ��ͬʱ��ͬԴ��ʵ����ܻ�ָ����ʵ�����ͬһ�����壬��ʱ��Ҫʹ��ʵ��ƥ�佫��ͬ����Դ��ͬ��������ݽ����ںϡ���ͬ�����Ҳ�����ijЩ��������ͬһ�����ݣ���ô����Щ���������Ҫ�����ںϼ����Ѳ�ͬ�ı����ںϡ�����ں϶��ɵ�֪ʶ����Ҫһ���洢�������Ľ��������֪ʶ�洢�����Ľ������������û���ѯ�����IJ�ͬ���ò�ͬ�Ĵ洢�ܹ��� NoSQL ���߹�ϵ���ݿ⡣ͬʱ���ģ��֪ʶ��Ҳ���ϴ����ݵ������������Ҫ��ͳ�Ĵ�����ƽ̨�� Spark ���� Hadoop �ṩ�����ܼ���������֧�ֿ������㡣
����1.1.3 ֪ʶ���㼰Ӧ��
����֪ʶ������Ҫ�Ǹ���ͼ���ṩ����Ϣ�õ�����������֪ʶ����ͨ��������߹��������������Ի�ȡ�����д��ڵ�����֪ʶ��������Ԥ�����Ԥ��ʵ��������Ĺ�ϵ��ͬʱʹ��������IJ�ͬ�㷨��֪ʶ�����ϼ����ȡ֪ʶͼ���ϴ��ڵ��������ṩ֪ʶ�������·����ͨ����һ�¼�⼼�����������е�������ȱ�ݡ�ͨ��֪ʶ����֪ʶͼ���Բ�������������Ӧ��������ṩ��ȷ���û�����Ϊ��Ӫ��ϵͳ�ṩDZ�ڵĿͻ����ṩ����֪ʶ��ר��ϵͳ�ṩ�������ݣ�����ʦ��ҽ������˾ CEO ���ṩ�������ߵ�������ṩ�����ܵļ�����ʽ��ʹ�û�����ͨ����Ȼ���Խ�����������Ȼ֪ʶͼ��Ҳ���ʴ�ز����ٵ���Ҫ�齨��
ͼ1
��������ͼ���Կ�����֪ʶͼ���漰���ļ����dz��࣬ÿһ�������Ҫר��ȥ�о��������Ѿ��кܶ��о��ɹ�������ƪ�������ƣ������ص����֪ʶͼ������֪ʶ����ļ������ļ�����
����1.2 ʵ���ϵʶ����
�������ʵ���ϵʶ�������� 1998 �� MUC��Message Understanding Conference������ MUC-7 �������룬Ŀ����ͨ������ϵģ��۵ķ�ʽ��ȥ�ı����ض��Ĺ�ϵ��1998 ���� ACE��Automatic Content Extraction���б�����Ϊ��ϵ����ʶ�������2009 �� ACE ���� TAC (Text Analysis Conference)����ϵ��ȡ�����뵽 KBP��knowledgeBase Population������IJ�������ӹ�ϵ�������ϣ���Ϊ������Close Domain���Ϳ�������Open IE�����ӷ����Ͽ���ʵ���ϵʶ���˴���ˮ��ʶ�����ɵ��˵��˵�ʶ����
��������ͳ��ѧ�ķ��������ı���ʶ��ʵ����ϵ������ת��Ϊ�������⡣����ͳ��ѧ�ķ�����ʵ���ϵʶ��ʱ��Ҫ����ʵ���ϵ��������Ϣȷ��ʵ���Ĺ�ϵ��Ȼ�����ڼල�ķ������������ı�ע���ݣ���˰�ල�����ල�ķ����ܵ��˸����ע��
������1���ලѧϰ��Zhou[13] �� Kambhatla �Ļ����ϼ����˻����������Ϣ�� WordNet��ʹ�� SVM ��Ϊ����������ʵ���ϵʶ���ȷ�ʴﵽ�� 55.5%��ʵ�����ʵ�������Ϣ��������������߹�ϵ��ȡ���ܣ� Zelenko[14] ����ʹ��dz��䷨����������С���������������ϵʵ����������������֮��ĺ˺�����ͨ��ѵ������ SVM ģ�͵ķ���������ʵ�����з֡������ں˺����ķ������������ٻ����ձ�ϵͣ������������ƶȼ������ƥ��Լ���Ƚ��ϸ�����ں����о��Ի��ں˺����Ľ��У�����Χ�ƸĽ��ٻ��ʡ�������ʱ������ƣ����ϵ����ࡢ���ѧϰ��ͼ������������óɹ�����Ϣ��ȡ��ת���˻�����ģ�͵��о�����ص����ϱ������Ϊ���Ա����� SemEval-2010 task 8[15]�����������緽�����о��У�Hashimoto[16] �������� Word Embedding �����ӱ�ע������ѧϰ�ض������ʶԵ�������������Ȼ���������뵽������������У��� SemEval-2010 task 8 ��ȡ���� F1 ֵ 82.8% ��Ч��������������ģ���������ص��Dz���Ҫ����̫���������һ����õ������д�������λ�õȣ��������������û������ϳ�ȡģ�ͣ�����ģ�Ϳ���ͬʱ��ȡʵ�����֮��Ĺ�ϵ�����ϳ�ȡģ�͵��ŵ��ǿ��Ա�����ˮ��ģ�ʹ��ڵĴ����ۻ�[17-22]�����бȽ��д����ԵĹ�����[20]���÷���ͨ�����ȫ�µ�ȫ��������Ϊ�㷨����Լ��������ͬʱ��߹�ϵ��ȡ��ʵ���ȡ��ȷ�ʣ��÷����� ACE �����ϱȴ�ͳ����ˮ�߷��� F1 ����� 1.5%������һ����� [22]������˫��� LSTM-RNN ģ��ѵ������ģ�ͣ���һ�� LSTM ������Ǵ�������λ�������ʹ�����ʶ��ʵ������͡�ѵ���õ��� LSTM �����ز�ķֲ�ʽ�����ʵ��ķ����ǩ��Ϣ��Ϊ�ڶ��� RNN ģ�͵����룬�ڶ��������ʵ��֮�������·�����ڶ���ѵ���Թ�ϵ�ķ��࣬ͨ��������ͬʱ�Ż� LSTM �� RNN ��ģ�Ͳ�����ʵ������һ����������������ϳ�ȡģ��[21]����ڹ�ϵ��������һ��������������������ˮ�߷����������ϳ�ȡ�������������мලѧϰ�������Ҫ������ѵ�����ϣ������ǶԻ���������ķ�������Ҫ���������Ͻ���ģ��ѵ���������Щ�������������ڹ������ģ�� Knowledge Base��
������2���루�����ලѧϰ����ලѧϰ��Ҫ�����������ı�ע��Ϣ����ѧϰ���ⷽ��Ĺ�����Ҫ�ǻ��� Bootstrap �ķ��������� Bootstrap �ķ�����Ҫ������������ʵ����Ϊ��ʼ���ӵļ��ϣ�Ȼ������ pattern ѧϰ��������ѧϰ��ͨ�����ϵĵ������ӷǽṹ�������г�ȡʵ����Ȼ�����ѧ����ʵ����ѧϰ�µ� pattern ������ pattern ���ϡ�Brin[23]����ͨ��������ʵ��ѧϰ����ģ�壬�������ϴ����ǽṹ���ı��г�ȡ�µ�ʵ����ͬʱѧϰ�µij�ȡģ�壬����Ҫ�����ǹ����� DIPRE ϵͳ��Agichtein[24]�� Brin �Ļ����϶��³�ȡ��ʵ�����п��Ŷȵ����ֺ����ƹ�ϵ������ģʽ�����ʵ���� Snowball ��ȡϵͳ���˺��һЩϵͳ������ Bootstrap �ķ������������������Ķ� pattern ���������Ӻ������������������ֲ��ԣ���������ǰϵͳ��ȡ����Ϲ������ģ pattern���� NELL��Never-EndingLanguage Learner��ϵͳ[25-26]��NELL ��ʼ��һ����������� pattern���Ӵ��ģ�� Web �ı���ѧϰ��ͨ����ѧϰ�������ݽ��д�������ȷ�ʣ�Ŀǰ�Ѿ������ 280 �����ʵ��
������3���ලѧϰ�� Bollegala[27]����������ժҪ�л�ȡ�;ۺϳ�ȡģ�壬��ģ����������ʵ��Դ��������������ϵ; Bollegala[28]ʹ�����Ͼ���(Co-clustering)�㷨�����ù�ϵʵ����ϵģ��Ķ�ż�ԣ�����˹�ϵģ�����Ч����ͬʱʹ�� L1 ���� Logistics �ع�ģ�ͣ��ڹ�ϵģ���������ɸѡ�������Եij�ȡģ�壬ʹ�ù�ϵ��ȡ��ȷ�ʺ��ٻ����϶�������ߡ�
�����ලѧϰһ�����������д��ڵĴ���������Ϣ�����࣬�ھ������Ļ����ϸ�����ϵ�������ھ���������ʹ�������������ϵ�͵�Ƶʵ���ٻ��ʵ͵����⣬����ලѧϰһ�����Եúܺõij�ȡЧ����
����1.3 ֪ʶ�ںϼ���
����֪ʶ�ںϣ�knowledge fusion��ָ���ǽ��������Դ��ȡ��֪ʶ�����ںϡ��봫ͳ�����ںϣ�datafusion��[29]�������Ҫ��ͬ�ǣ�֪ʶ�ںϿ���ʹ�ö��֪ʶ��ȡ����Ϊÿ���������ÿ������Դ�г�ȡ��Ӧ��ֵ���������ں�δ���Ƕ����ȡ����[30]���ɴˣ�֪ʶ�ںϳ���Ӧ�Գ�ȡ��������ʵ�������ܴ��ڵ������⣬���������ں϶�������һ�����������Dz�ͬ��ȡ����ͨ��ʵ�����Ӻͱ���ƥ����ܲ�����ͬ�Ľ�������⣬֪ʶ�ںϻ���Ҫ���DZ�����ںϺ�ʵ�����ںϡ�
��������[30]���ȴ����е������ںϷ�������ѡ�����ڲ�����������ʵġ�����ʹ�û��� MapReduce ��ܵġ���ǰ;�����·�����Ȼ�����Щ��ѡ���ķ����������¸Ľ�������֪ʶ�ںϣ���ÿ����ȡ����ͬÿ����ϢԴ��ԣ�ÿ����Ϊ�����ں������е�һ������Դ�������ͱ���˴�ͳ�������ں����Ľ����������ںϷ���ʹ��������ʣ�����ԭ������ٶ�ֵ������֪ʶ�ں��е����������Ļ��� MapReduce �Ŀ�ܡ�����[31]���һ����ͨ����ͬ��������õ���֪ʶ��Ƭ�����ṹ�����ܽᣩ�ں������ķ��������һ��ʵ���ѯ����ͬ����������ܷ��ز�ͬ��֪ʶ��Ƭ������ͬһ����������Ҳ���ܷ��ض��֪ʶ��Ƭ������Щ֪ʶ��Ƭ�ں�����ʱ��ͬ����[30]������ķ������ƣ���֪ʶ�ں��е���ά���⽫Ϊ��ά���⣬��Ӧ�ô�ͳ�������ںϼ���������������[31]�����һ���µĸ��ʴ���㷨��������ѡһ��֪ʶ��Ƭ���п���ָ���ʵ�壬�������һ������ѧϰ�ķ�����������ƥ�䡣
������֪ʶ�ںϼ����У�����ƥ������ŷdz���Ҫ�Ľ�ɫ���ṩ�˸������ʵ��֮��Ķ�Ӧ��ϵ����ֹĿǰ�������Ѿ�����˸��ָ����ı���ƥ���㷨��һ����Է�Ϊģʽƥ�䣨schema matching����ʵ��ƥ�䣨instance matching����Ҳ��������ͬʱ����ģʽ��ʵ����ƥ��[32-34]���Ӽ�����������������ƥ��ɷ�Ϊ����ʽ���������ʷ���������ͼ�ķ���������ѧϰ�ķ����ͻ��������ķ���������Χ��ģʽƥ���ʵ��ƥ�䣬������ܸ��Է����м������д����Ե�ƥ�䷽����
����ģʽƥ����ҪѰ�ұ��������Ժ���֮��Ķ�Ӧ��ϵ������[35]��[36]�����Ƚ��꾡������������[37]���һ���Զ�������ƥ�䷽�����÷������������� WordNet ֮��Ĵʵ��Լ�����Ľṹ����Ϣ����ģʽƥ�䣬Ȼ������ݼ�Ȩƽ���ķ�������������������һЩģʽ��patterns������һ���Լ�飬ȥ����Щ���²�һ�µĶ�Ӧ��ϵ���ù��̿�ѭ���ģ�ֱ�������ҵ��µĶ�Ӧ��ϵΪֹ������[38]Ҳ�ǿ��Ƕ���ƥ���㷨�Ľ�ϣ����û��������һЩ���ƶȼ����㷨������ n-gram �ͱ༭���룬�����㷨����Ľ�����ݼ�Ȩ��ͽ��кϲ����������˸���IJ�ι�ϵ��һЩ����֪ʶ�����ͨ���û������Ȩ�ؽ��кϲ���Ϊ��Ӧ�Դ��ģ�ı��壬����[39]���һ��ʹ��ê��anchor����ϵͳ����ϵͳ��һ������������������Ƹ���Ϊ��㣬������Щ����ĸ�������Ӹ�����ھ���Ϣ�ع���СƬ�Σ������ҳ�ƥ��ĸ�����ҳ���ƥ��ĸ�����ֿ���Ϊ�µ�ê��Ȼ���ٸ����ھ���Ϣ�����µ�Ƭ�Ρ��ù��̲��ϵ��ظ���ֱ��δ�ҵ��µ�ƥ������ʱֹͣ������[40]���Էֶ���֮��˼�봦�����ģ���壬�÷����ȸ��ݱ���Ľṹ������л��ֻ����飬Ȼ��Ӳ�ͬ�����õ������л���ê��ƥ�䣬�����ê��ָ����ƥ��õ�ʵ��ԣ�����ٴ�ƥ���������ҳ���Ӧ�ĸ�������ԡ����е�ƥ�䷽��ͨ���ǽ����ƥ���㷨���ϣ����ü�Ȩƽ�����Ȩ��͵ķ�ʽ���кϲ������ǣ����ڱ���ṹ�IJ��Գ��Ե����������̶ֹ��ļ�Ȩ�����Գ����㡣����[41]���ڱ�Ҷ˹���ߵķ�����С�����һ����̬�ĺϲ��������÷������Ը��ݱ�����������ڼ���ÿ��ʵ��Ե����ƶ�ʱ��̬��ѡ��ʹ���ļ���ƥ���㷨����κϲ���Щ�㷨��������Դ����˺ܺõ�ƥ������
����ʵ��ƥ���������칹֪ʶԴ֮��ʵ���Ե����ƶȣ������ж���Щʵ���Ƿ�ָ������������ͬʵ�塣������꣬���� Web 2.0 ������ Web �����IJ��Ϸ�չ��Խ��Խ������������������зḻʵ���ͱ���ģʽ���ص㣬��ʹ����ƥ����о����������Ĵ�ģʽ��ת�Ƶ�ʵ����[42]������[43]���һ����ѵ���ķ�������ʵ��ƥ�䣬�÷������ȸ��� owl:sameAs�����������ԣ�functional properties���ͻ�����cardinalities������һ���ˣ�kernel�����ٸ�������Ƚ����Ե�����ֵ�Եݹ�ĶԸú˽�����չ������[44]�������еľֲ����й�ϣ��locality-sensitivehashing��������������ʵ��ƥ��Ŀ���չ�ԣ��÷���������Ҫ��������ʵ�������Է��������ȣ�Ȼ��ʹ�÷ָ�õ��ַ�������ʵ�����ƶȡ�����[45]����ʹ�������ռ�ģ�ͱ�ʾʵ������������Ϣ���ٻ��ڹ�����õ���������inverted indexes����ȡ�����ƥ���ѡ����ʹ���û����������ֵ�Ժ�ѡ���й��ˣ����������ƥ���ѡ���ƶ�������Ϊ���ϵ��������룬�ɴ˳�ȡ��ƥ��������Ȼ���з��������в������ڴ������ģ�����ʵ��ƥ�����⣬����ͬʱ��֤��Ч�߾�����Ȼ�Ǹ��ܴ����ս������[46]�����һ�������Ŀ�ܣ���������������Ե�����ƥ�䷽�������Ч�ʣ�ͬʱ�������ƶȴ����ķ�������һ����Ȩָ��������ȷ��ʵ��ƥ��ĸ߾��ȡ�
����1.4 ʵ�����Ӽ���
���������ԺͶ���������Ȼ���ԵĹ������ԣ�Ҳ��ʵ�����ӵĸ����ѵ㡣����ھ���ࡢ������Ч������֤�ݣ���Ƹ������ܵ������㷨��Ȼ��ʵ������ϵͳ�ĺ����о����⣬ֵ�ý�һ���о������水�ղ�ͬ��ʵ�����緽�����з��ࡣ
�������ڸ�������ģ�ͷ����������������[47]�����һ�����ɸ���ģ�ͣ�����ѡʵ�� e ������ijҳ���еĸ��ʡ��ض�ʵ�� e ����ʾΪʵ��ָ����ĸ����Լ�ʵ�� e �������ض��������еĸ���������ˣ��õ���ѡʵ��ͬʵ��ָ����֮������ƶ�����ֵ��Blanco �� Ottaviano ����[48]���������������ѯʵ�����ӵĸ���ģ�ͣ��÷���������ɢ�м�����������֪ʶ����Ч�������ʵ�����ӵ�Ч�ʡ�
������������ģ�͵ķ�����Zhang ����[49]ͨ��ģ���Զ����ı��е�ʵ��ָ�ƽ��б�ע������ѵ�����ݼ�����ѵ�� LDA ����ģ�ͣ�Ȼ�����ʵ��ָ�ƺͺ�ѡʵ����������������ƶȴӶ�����õ�Ŀ��ʵ�塣�����µ���[50]����˶��û�����Ȥ���⽨ģ�ķ��������ȹ�����ϵͼ��ͼ�а����˲�ͬ����ʵ�����������ϵ��Ȼ�����þֲ���Ϣ�Թ�ϵͼ��ÿ������ʵ�帳���ʼ��Ȥֵ��������ô����㷨�Բ�ͬ����ʵ�����Ȥֵ���д����õ�������Ȥֵ��ѡ����������Ȥֵ�ĺ�ѡʵ�塣
��������ͼ�ķ�����Han ����[51]������һ�ֻ���ͼ��ģ�ͣ�����ͼ�ڵ�Ϊ����ʵ��ָ�ƺ����к�ѡʵ�壻ͼ�ı߷�Ϊ���࣬һ����ʵ��ָ�ƺ����Ӧ�ĺ�ѡʵ��֮��ıߣ�Ȩ��Ϊʵ��ָ�ƺͺ�ѡʵ��֮��ľֲ��ı����ƶȣ����ôʴ�ģ�ͺ����Ҿ������ó�����һ���Ǻ�ѡʵ��֮��ıߣ�Ȩ��Ϊ��ѡʵ��֮���������ضȣ����ùȸ������㡣�㷨���Ȳɼ���ͬʵ��ij�ʼ���Ŷȣ�Ȼ��ͨ��ͼ�еı߶����ŶȽ��д�������ǿ��Gentile �� Zhang[52]��������˻���ͼ�������ϵ������ʵ�����緽�����÷�����ά���ٿ��Ͻ�������ͼ��ģ�ͣ�Ȼ���ڸ�ģ���ϼ����������ʵ��ĵ÷ִӶ�ȷ����Ŀ��ʵ�壬�÷���������������ȡ���˽ϸߵ�ȷ�ʡ�Alhelbawy ����[53]Ҳ���û���ͼ�ķ�����ͼ�еĽڵ�Ϊ���еĺ�ѡʵ�壬�߲������ַ�ʽ������һ����ʵ��֮���ά���ٿ����ӣ���һ����ʹ��ʵ����ά���ٿ������о��ӵĹ��֡�ͼ�еĺ�ѡʵ��ڵ�ͨ����ʵ��ָ�Ƶ����ƶ�ֵ�������ʼֵ������ PageRank ѡ��Ŀ��ʵ�塣Hoffart ����[54]ʹ��ʵ���������ʣ�ʵ��ָ�ƺͺ�ѡʵ������������ƶȣ��Լ���ѡʵ��֮����ھ��Թ���һ����Ȩͼ������ѡ���һ����ѡʵ����ܼ���ͼ��Ϊ����ܵ�Ŀ��ʵ������ʵ��ָ�ơ�
�����������������ķ�������������������[55]�����һ������ʵ�������ʵ���ʾѵ���������÷������������ݽ����Ա��룬�������������ģ�����мල�ķ�ʽѵ��ʵ���ʾ�����������ʾ���ƶȶԺ�ѡʵ����������÷�����һ�־ֲ��Է�����û�п���ͬһ�ı��й�ͬ���ֵ�ʵ�������ԡ��ƺ��Ⱥͼ�������[56]������������������֪ʶͼ�ף������һ�ֻ���ͼ�İ�ලʵ�������巽���������������ģ�͵õ���ʵ��������������Ϊͼ�еı�Ȩֵ����ʵ�����ó�����������֪ʶͼ�� NGD �� VSM[57]�������� Wikipedia anchor links �����ڹ����Բ����ϻ��������������϶����и��õIJ��Խ������� NGD �� VSM������ DNN[58]�����������������ڹ����Բ����ϻ��������������϶����и��õĹ����Ժ��ߵ�ȷ�ԡ����÷����������㲻�㣬һ�����ڹ�������������ģ��ʱ���ôʴ��ӷ�����û�п��������Ĵ�֮��λ�ù�ϵ������һ����������Ĺ����У�������ͼģ��û�г������������ʵ�壬��Ȩֵ�Ͷ���÷�����δ����ʵ�����ӱ��ֲ��䣬��û��Ϊ����������ʵ��������Ϣ����
����1.5 ֪ʶ��������
����֪ʶ���������Դ��Եط�Ϊ���ڷ��ŵ������ͻ���ͳ�Ƶ����������˹����ܵ��о��У����ڷ��ŵ�����һ���ǻ��ھ�������һ��ν�������������������߾������ı��죨����˵ȱʡ���������ڷ��ŵ��������Դ�һ�����е�֪ʶͼ�ף����ù����������µ�ʵ����ϵ�������Զ�֪ʶͼ�������ij�ͻ��⡣����ͳ�Ƶķ���һ��ָ��ϵ����ѧϰ������ͨ��ͳ�ƹ��ɴ�֪ʶͼ����ѧϰ���µ�ʵ����ϵ��
����1.5.1 ���ڷ���������������
����Ϊ��ʹ����������ͬʱ�߱���ʽ�������Ч������һЩ�о���Ա������״�����tractable���������ԣ����ҿ�����һЩ���û�����������ϵͳ����Щϵͳ�������ʹ����Ը���������һϵ�������ԣ�ͳ����������deion logic�����õ���ѧ�����ҵ��㷺��ע��������Щϵͳ������Ч�����������������������ݵ���������û�ܵõ��㷺Ӧ�á���һ���ֱ������ִ�ѧ�� Ian Horrocks ���ڴ��ƣ��������� FaCT ϵͳ���Դ���һ���Ƚϴ��ҽ�����ﱾ�� GALEN���������ܱ��������Ƶ�������Ҫ�õöࡣ���������ճ�Ϊ�� W3C �Ƽ��� Web �������� OWL ����������
������Ȼ���������������Ż�ȡ���˺ܴ�Ľ�չ�����ǻ��Ǹ����������������ٶȣ��ر��ǵ����ݹ�ģ��Ŀǰ�Ļ����ڴ�ķ�����������������¡�Ϊ��Ӧ����һ��ս��������꣬�о���Ա��ʼ���ǽ��������� RDFS ����������������������Ч�ʺͿ���չ�ԣ�����ȡ���˺ܶ�ɹ����������������������IJ��м�����Ϊ�������ࣺ1�����������µĶ�ˡ��ദ����������������̣߳�GPU �����ȣ�2����������»�������ͨ�ŵķֲ�ʽ���������� MapReduce �����ܡ�Peer-To-Peer �����ܵȡ��ܶ������������Щ����ʵ�ָ�Ч�IJ���������
�������������µIJ��м����Թ����ڴ�ģ��Ϊ�ص㣬��������������������ʱ��Ч�ʡ�����ʵʱ��Ҫ��ϸߵ�Ӧ�ó��������ַ�����Ϊ��ѡ�����ڱ��������ϵ͵����ԣ����� RDFS��OWL EL�����������µIJ��м�����������������������Ч�ʡ�Goodman ������[59]�����ø����ܼ���ƽ̨ Cray XMT ʵ���˴��ģ�� RDFS ��������������ƽ̨������Դ�������������������������ڴ���ɡ�Ȼ�����ڼ�����Դ����ƽ̨���ڴ�ʹ���ʵ��Ż���Ϊ�˲��ɱ�������⡣Motik ������[60]�����н� RDFS���Լ������������ߵ� OWL RL �ȼ۵�ת��Ϊ Datalog ����Ȼ������ Datalog �еIJ����Ż�����������ڴ��ʹ�������⡣��[61]�У����߳������ò����봮�еĻ�Ϸ���������OWL RL������Ч�ʡ�Kazakov ������ [62]����������ö��̼߳���ʵ�� OWL EL ����(classification)�ķ�������ʵ�������� ELK��
�������ܵ���������������������������������ܵ����������ڼ�����Դ���ޣ������ڴ棬�洢�����������������Ŀ������ԣ�scalability���ܵ���ͬ�̶ȵ����ơ���ˣ��ܶ�����÷ֲ�ʽ����ͻ�ƴ��ģ���ݵĴ������ޡ����ַ������ö�����Ⱥ��ʵ�ֱ���������
����Mavin[63]������������ Peer-To-Peer �ķֲ�ʽ���ʵ�� RDF ���������Ĺ�����ʵ�������������÷ֲ�ʽ����������ɺܶ��ڵ�������������ɵĴ��������������ܶ������ MapReduce �Ŀ�Դʵ�֣��� Hadoop��Spark �ȣ��������˴��ģ������������������н�Ϊ�ɹ���һ�������� Urbani ������ 2010 �깫��������ϵͳ WebPIE [64]��ʵ����֤ʵ���ڴ�Ⱥ�Ͽ�������ϰ��ڵ� RDF ��Ԫ���������������������������о�����˻��� MapReduce �� OWL RL ��ѯ�㷨[65]������ MapReduce ��ʵ�� OWL EL ����������㷨�� [66]�������ʵ��֤�� MapReduce ����ͬ�����Խ�����ģ�� OWL EL ������������[67]�Ĺ����У���һ����չ OWL EL ������������ʹ�����������ڶ�����м���ƽ̨��ɡ�
����1.5.2 ����ͳ�Ƶ���������
����֪ʶͼ���л���ͳ�Ƶ���������һ��ָ��ϵ����ѧϰ�������������һЩ���͵ķ�����
����ʵ���ϵѧϰ����
����ʵ���ϵѧϰ��Ŀ����ѧϰ֪ʶͼ����ʵ����ʵ��֮��Ĺ�ϵ���ⷽ��Ĺ����dz��࣬Ҳ���������֪ʶͼ��һ���Ƚ��ȵ��о�����������[68]�ķ��࣬���Է�ΪDZ������ģ�ͺ�ͼ����ģ�����֡�DZ������ģ��ͨ��ʵ����DZ��������������Ԫ�顣����˵��Ī�Ի��ŵ������ѧ����һ�����ܽ���������һ�����������ҡ�Nickel������[69]�и�����һ����ϵDZ������ģ�ͣ���Ϊ˫���ԣ�bilinear��ģ�ͣ���ģ�Ϳ�����DZ������������������ѧϰDZ�ڵ�ʵ���ϵ��Drumond ������[70]��Ӧ�����������������ֽ�ģ����ѧϰ֪ʶͼ���е�DZ�ڹ�ϵ��
�������루translation��ģ��[71]��ʵ�����ϵͳһӳ������ά�����ռ��У�����Ϊ��ϵ�����г�����ͷʵ�巭����βʵ���DZ����������ˣ�ͨ�����Ա������ռ��д�������DZ��������ʵ�������ԣ����ǿ��Եõ�֪ʶͼ����DZ�ڵ���Ԫ���ϵ��ȫϢǶ�루Holographic Embedding��HolE��ģ��[72]�ֱ�����Բ����ؼ�����Ԫ�����ϱ�ʾ������Բ�ܾ�������ϱ�ʾ�лָ���ʵ�弰��ϵ�ı�ʾ���������ֽ�ģ�����ƣ�HolE ���Ի�ô�����ʵ�彻����ѧϰDZ�ڹ�ϵ��������Ч������ѵ�������������ѵ��Ч�ʡ�
��������ͼ����ģ�͵ķ�����֪ʶͼ���й۲쵽����Ԫ��ıߵ�������Ԥ��һ�����ܵıߵĴ��ڡ����͵ķ����л��ڻ��ڹ���������ILP���ķ���[73]�����ڹ��������ھ�ARM���ķ���[74]��·������path ranking���ķ���[75]������ ILP �ķ����ͻ��� ARM �ķ����Ĺ�֮ͬ������ͨ���ھ�ķ�����֪ʶͼ���г�ȡһЩ����Ȼ�����Щ����Ӧ�õ�֪ʶͼ���ϣ��Ƴ��µĹ�ϵ����·���������Ǹ�������ʵ�����ͨ·����Ϊ�������ж�����ʵ���Ƿ�����ij����ϵ��
��������������typeinference������
����֪ʶͼ���ϵ���������Ŀ����ѧϰ֪ʶͼ���е�ʵ������֮������ڹ�ϵ��SDType[76]������Ԫ�������ν�����������Ե�ͳ�Ʒֲ���Ԥ��ʵ�������͡��÷��������������ⵥ����Դ��֪ʶͼ�ף����������������ݼ�������������Tipalo[77]��LHD[78]��ʹ�� DBpedia �����е� abstract ���ݣ������ض�ģʽ����ʵ�����͵ij�ȡ��������������ض��ṹ���ı����ݣ�����չ������֪ʶ�⡣
����ģʽ���ɣ�schemainduction������
����ģʽ���ɷ���ѧϰ����֮��Ĺ�ϵ����Ҫ�л��� ILP �ķ����ͻ��� ARM �ķ�����ILP ����˻���ѧϰ������̼�����ʹ�����ǿ��Դ�ʵ���ͱ���֪ʶ�л�������ۡ�Lehmann ����[79]����������¾�������ѧϰ�������ĸ���幫���ķ�����������һ��ĸ�����������ʼ����������ʽ��������ʹ�ø�������⻯�����յõ�����Ķ��塣Ϊ�˴����� DBpedia �������ģ���������ݣ��÷�����[80]�еõ���һ������չ����Щ�������� DL-Learner[81]�е���ʵ�֡�V?lker ������[82]�н����˴�֪ʶͼ�������ɸ����ϵ��ͳ�Ʒ������÷���ͨ�� SPARQL ��ѯ����ȡ��Ϣ�����Թ����������Ȼ��ʹ�� ARM ��������������ھ��һЩ������ĸ����ϵ�������ǵĺ��������У�ʹ�ø����������ھ���ѧϰ���������ϵ[83]����������[84]�и����˷ḻ����������
����2 ����֪ʶͼ��
�����������Ƚ��ܵ�ǰ���緶Χ��֪���ĸ��������ģ����֪ʶͼ�ף����� DBpedia[85][86]��Yago[87][88]��Wikidata[89]��BabelNet[90][91]��ConceptNet[92][93]�Լ�Microsoft Concept Graph[94][95]�ȡ�Ȼ��������Ŀ���֪ʶͼ��ƽ̨ OpenKG��
����2.1 ����֪ʶͼ��
����DBpedia ��һ�����ģ�Ķ����ٿ�֪ʶͼ�ף�����Ϊ��ά���ٿƵĽṹ���汾��DBpedia ʹ�ù̶���ģʽ��ά���ٿ��е�ʵ����Ϣ���г�ȡ������ abstract��infobox��category �� page link ����Ϣ��ͼ 2 ʾ������ν�ά���ٿ��е�ʵ�塰Busan���� infobox ��Ϣת���� RDF ��Ԫ�顣DBpedia Ŀǰӵ�� 127 �����Եij�����ǧ�˰����ʵ�������ڸ� RDF ��Ԫ�飬������Ϊ�������ݵĺ��ģ��������������ݼ�������ʵ��ӳ���ϵ�������ݳ�������[96]��DBpedia �� RDF ��Ԫ�����ȷ�ʴ� 88%��DBpedia ֧�����ݼ�����ȫ���ء�
����Yago ��һ��������ά���ٿ��� WordNet[97]�Ĵ��ģ���壬�������ƶ�һЩ�̶��Ĺ����ά���ٿ���ÿ��ʵ��� infobox ���г�ȡ��Ȼ������ά���ٿƵ�category����ʵ������ƶϣ�Type Inference������˴�����ʵ�������֮��� IsA ��ϵ���磺��Elvis Presley�� IsA ��American Rock Singers���������ά���ٿƵ� category �� WordNet �е� Synset��һ�� Synset ��ʾһ���������ӳ�䣬�Ӷ������� WordNet �ϸ���� Taxonomy ��ɴ��ģ����Ĺ���������ʱ������ƣ�Yago �Ŀ�����ԱΪ�ñ����е� RDF ��Ԫ��������ʱ����ռ���Ϣ���Ӷ������ Yago2[98]�Ĺ�������������ͬ�ķ����Բ�ͬ����ά���ٿƵĽ��г�ȡ������� Yago3[99]�Ĺ�����Ŀǰ��Yago ӵ�� 10 ������Լ 459 ���ʵ�壬2400 ��� Facts��Yago �� Facts����ȷ��ԼΪ 95%��Yago ֧�����ݼ�����ȫ���ء�

ͼ2
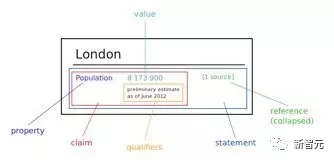
����Wikidata ��һ����������Э���༭�Ķ����ٿ�֪ʶ�⣬����ά��ý�����ᷢ��������ά���ٿơ�ά���Ŀ⡢ά�����ε���Ŀ�нṹ��֪ʶ���г�ȡ���洢��������Wikidata �е�ÿ��ʵ����ڶ����ͬ���Եı�ǩ���������������Լ�������statement�������� Wikidata �����ʵ�塰London�������ı�ǩ���ء�������������Ӣ�������Լ�ͼ 3 ������һ�����ڡ�London���������ľ������ӡ���London����һ��������һ�� claim ��һ�� reference ��ɣ�claim ����property:��Population����value:��8173900���Լ�һЩ qualifiers����ע˵������ɣ��� reference ���ʾһ�� claim �ij���������Ϊ��ֵ��Ŀǰ Wikidata Ŀǰ֧�ֳ��� 350 �����ԣ�ӵ�н� 2500 ���ʵ�弰���� 7000 �������[100]������Ŀǰ Freebase ������ Wikidata �Ͻ���Ǩ���Խ�һ��֧�� Google ������������Wikidata ֧�����ݼ�����ȫ���ء�
ͼ3
����BabelNet ��Ŀǰ���緶Χ�����Ķ����ٿ�ͬ��ʵ䣬�������ɱ���Ϊһ���ɸ��ʵ�塢��ϵ���ɵ��������磨Semantic Network����BabelNet Ŀǰ�г��� 1400 �����Ŀ��ÿ����Ŀ��Ӧһ�� synset��ÿ�� synset �������б�����ͬ����IJ�ͬ���Ե�ͬ��ʡ����磺���й��������л�����������China���Լ���people��srepublic of China����������һ�� synset �С�BabelNet �� WordNet �е�Ӣ�� synsets ��ά���ٿ�ҳ�����ӳ�䣬������ά���ٿ��еĿ�����ҳ�������Լ�����ϵͳ���Ӷ��õ� BabelNet �ij�ʼ�汾��Ŀǰ BabelNet �������� Wikidata��GeoNames��OmegaWiki �ȶ�����Դ����ӵ�� 271 �����汾������ BabelNet �еĴ�����Դ��Ҫ����ά���ٿ��� WordNet ֮���ӳ�䣬��ӳ��Ŀǰ����ȷ�ʴ�Լ�� 91%���������ݼ���ʹ�ã�BabelNet Ŀǰ֧�� HTTP API ���ã������ݼ�����ȫ������Ҫ���������õ���֤�������ɡ�
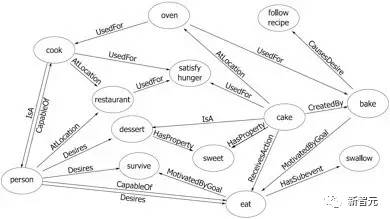
����ConceptNet ��һ�����ģ�Ķ����Գ�ʶ֪ʶ�⣬�䱾��Ϊһ������Ȼ���Եķ�ʽ�������ೣʶ�Ĵ����������硣ConceptNet ��Դ��һ���ڰ���Ŀ Open Mind Common Sense���� 1999 �꿪ʼͨ���ı���ȡ���ڰ����ں�����֪ʶ���еij�ʶ֪ʶ�Լ����һЩ��Ϸ�Ӷ����ϻ�ȡ��ʶ֪ʶ��ConceptNet �й�ӵ�� 36 �̶ֹ��Ĺ�ϵ���� IsA��UsedFor��CapableOf �ȣ�ͼ 4 ������һ����������ӣ����п��Ը����������˽� ConceptNet �Ľṹ��ConceptNet Ŀǰӵ�� 304 �����Եİ汾�����г��� 390 ������2800 ���������statements�������������бߵ�����������ȷ��ԼΪ 81%�����⣬ConceptNet Ŀǰ֧�����ݼ�����ȫ���ء�
ͼ4
����Microsoft Concept Graph ��һ�����ģ��Ӣ�� Taxonomy��������Ҫ�������Ǹ�����Լ�ʵ������ͬ�������е�ʵ�壩������ IsA ��ϵ�����в������� instanceOf �� subclassOf ��ϵ��Microsoft Concept Graph ��ǰ���� Probase�������Զ����س�ȡ����ʮ����ҳ�����������ѯ��¼������ÿһ�� IsA ��ϵ������һ������ֵ������֪ʶ���е�ÿ�� IsA ��ϵ���Ǿ��Եģ����Ǵ���һ�������ĸ���ֵ��֧�ָ���Ӧ�ã�����ı����⡢���� taxonomy �Ĺؼ�����������ά����������ȡ�Ŀǰ��Microsoft Concept Graph ӵ��Լ 530 ������1250 ���ʵ���Լ� 8500 ��� IsA ��ϵ����ȷ��ԼΪ 92.8%�����������ݼ���ʹ�ã�MicrosoftConcept Graph Ŀǰ֧�� HTTP API ���ã������ݼ�����ȫ������Ҫ���������õ���֤�������ɡ�
������������֪ʶͼ���⣬����Ŀǰ���õĴ��ģ����֪ʶͼ���� Zhishi.me[101]��Zhishi.schema[102]��XLore[103]�ȡ�Zhishi.me �ǵ�һ�ݹ��������������ݵĹ������� DBpedia ���ƣ�Zhishi.me ����ָ���̶��ij�ȡ����ٶȰٿơ������ٿƺ�����ά���ٿ��е�ʵ����Ϣ���г�ȡ������ abstract��infobox��category ����Ϣ��Ȼ���Դ�Բ�ͬ�ٿƵ�ʵ����ж��룬�Ӷ�������ݼ������ӡ�Ŀǰ Zhishi.me ��ӵ��Լ 1000 ���ʵ����һ����ǧ��� RDF ��Ԫ�飬�������ݿ���ͨ������ SPARQL Endpoint ��ѯ�õ���Zhishi.schema ��һ�����ģ������ģʽ��Schema��֪ʶ�⣬�䱾����һ���������磬���а������ָ����Ĺ�ϵ����equal��related��subClassOf��ϵ��Zhishi.schema��ȡ���罻վ��ķ���Ŀ¼(Category Taxonomy)����ǩ�ƣ�Tag Cloud����Ŀǰӵ��Լ40������ĸ�����150��RDF��Ԫ�飬��ȷ��ԼΪ84%����֧�����ݼ�����ȫ���ء�XLore ��һ�����͵���Ӣ��֪ʶͼ�ף���ּ�ڴӸ��ֲ�ͬ����Ӣ�����߰ٿ��г�ȡ RDF ��Ԫ�飬��������Ӣ��ʵ���Ŀ��������ӡ�Ŀǰ��XLore ��Լ�� 66 ������5 ������ԣ�1000 ���ʵ�壬�������ݿ���ͨ������ SPARQL Endpoint ��ѯ�õ���
����2.2 ���Ŀ���֪ʶͼ�����˽���
�������Ŀ���֪ʶͼ�����ˣ�OpenKG��ּ���ƶ�����֪ʶͼ�Ŀ����뻥�����ƶ�֪ʶͼ�������й����ռ���Ӧ�ã�Ϊ�й��˹����ܵķ�չ�Լ����´�ҵ�������ס������Ѿ���� OpenKG.CN ����ƽ̨����ͼ 5 ��ʾ��Ŀǰ���� 35 �һ�����פ�������˹���������֪ʶͼ����Դ�ļ��룬�� Zhishi.me�� CN-DBPedia, PKUBase�����Ѿ������������ڳ�ʶ��ҽ�ơ����ڡ����С����е� 15 ����Ŀ�Ŀ���֪ʶͼ�ס�
����
ͼ5 ���Ŀ���֪ʶͼ������
����3 ֪ʶͼ�����鱨�����İ���
����3.1 ��ƱͶ���鱨����
����ͨ��֪ʶͼ����ؼ������й��顢�걨����˾���桢ȯ���о����桢���ŵȰ�ṹ������ͷǽṹ���ı������������Զ���ȡ��˾�Ĺɶ����ӹ�˾����Ӧ�̡��ͻ���������顢�������ֵ���Ϣ����������˾��֪ʶͼ�ס���ij����۾����¼�������ҵ����¼�������ʱ��ȯ�̷���ʦ������Ա������˾��������Ͷ���о���Ա����ͨ����ͼ���������εķ������õ�Ͷ�ʾ��ߣ���������������������ͨѶ���ڵ���Ϣ����֮���������������ͨѶ�Ŀͻ���Ӧ�̡���������Լ��������ֵĹ�ϵͼ�ף�����������ͨѶͣ�Ƶ�����¿��ٵ�ɸѡ����Ӱ��Ĺ��ʹ������й�˾�Ӷ��ھ�Ͷ�ʻ�����߽���Ͷ����Ϸ��տ��ƣ�ͼ6����
����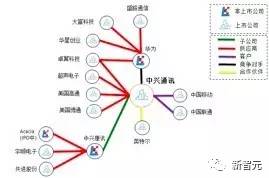
ͼ6 ��ƱͶ���鱨����
����2.2 �����鱨����
����ͨ���ں���ҵ���������ʽ�����ϸ��ͨ�������С�ס�ޡ����̡�˰�����Ϣ���������ġ��ʽ��˻�-��-��˾������֪ʶͼ�ס�ͬʱ�Ӱ�����������¼�ȷǽṹ���ı��г�ȡ��(�ܺ��ˡ������ˡ�������)���¡����֯�����š�ʱ�䡢�ص����Ϣ�����Ӳ����䵽ԭ�е�֪ʶͼ�����γ�һ��������֤�����������������졢���졢���н��а������������ھ�ͬ��������к����������ʽ��˻�������һ��ʱ�����д����ʽ����������е�ij���˻���ʱ��ܿ����ǷǷ����ʣ�ϵͳ����Ԥ����ͼ7����
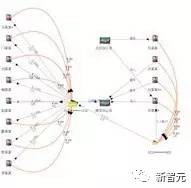
ͼ7 �����鱨����
����3.3 ����թ�鱨����
����ͨ���ں����Բ�ͬ����Դ����Ϣ����֪ʶͼ�ף�ͬʱ��������ר�ҽ���ҵ��ר�ҹ�������ͨ�����ݲ�һ���Լ�⣬���û��Ƴ���֪ʶͼ����ʶ��DZ�ڵ���թ���ա�����������xx�ͽ������x��д��ϢΪͬ�£�������������д�Ĺ�˾��ȴ��һ��, �Լ�ͬһ���绰����������������ˣ���Щ��һ���Ժܿ�������թ��Ϊ ��ͼ8����
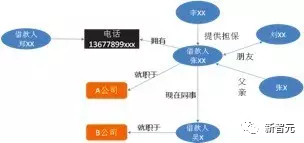
ͼ8 ����թ�鱨����
����4 �ܽ�
����֪ʶͼ����֪ʶ���̵�һ����֧����֪ʶ����������������Ϊ���ۻ��������ҽ���˻���ѧϰ����Ȼ���Դ�����֪ʶ��ʾ�����������³ɹ����ڴ����ݵ��ƶ����ܵ���ҵ���ѧ����Ĺ㷺��ע��֪ʶͼ���ڽ�����������ı�������ͼ���������ⷢ����Ҫ���á�Ŀǰ��֪ʶͼ���о��Ѿ�ȡ���˺ܶ�ɹ����γ���һЩ���ŵ�֪ʶͼ�ס����ǣ�֪ʶͼ�ķ�չ�����������ϰ������ȣ���Ȼ������ʱ���Ѿ������˺��������ݣ��������ݷ���ȱ���淶�����������������ߣ�����Щ�������ھ��������֪ʶ��Ҫ���������������⡣��Σ���ֱ�����֪ʶͼ����ȱ����Ȼ���Դ����������Դ���ر��Ǵʵ���ѷ�ʹ�ô�ֱ����֪ʶͼ�������ۺܴ����֪ʶͼ����ȱ����Դ�Ĺ��ߣ�Ŀǰ�ܶ��о����������߱�ʵ���ԣ����Һ����й��߷�����ͨ�õ�֪ʶͼ����ƽ̨������ʵ�֡�
�����ο���������ԭ���Ķ����ӣ�
����http://tie.istic.ac.cn/ch/reader/view_abstract.aspx?file_no=201701002&flag=1&from=timeline&isappinstalled=0
��������ת����PaperWeekly���ش˸�л��


 �Ӻ���
�Ӻ���  ������
������
 ����Ա
����Ա
 Post By��2017/3/20 16:47:41 [ֻ��������]
Post By��2017/3/20 16:47:41 [ֻ��������]






